Introducing Mab2Rec: A Multi-armed Bandit Recommender Library
By Bernard Kleynhans and Serdar Kadioglu
Building and deploying recommendation models require non-trivial effort and investment in sophisticated tools and expertise to perform robust feature engineering, model selection, and evaluation. To support data scientists and engineers in building and deploying recommender models, we release Mab2Rec, a Python library for building bandit-based recommendation algorithms.
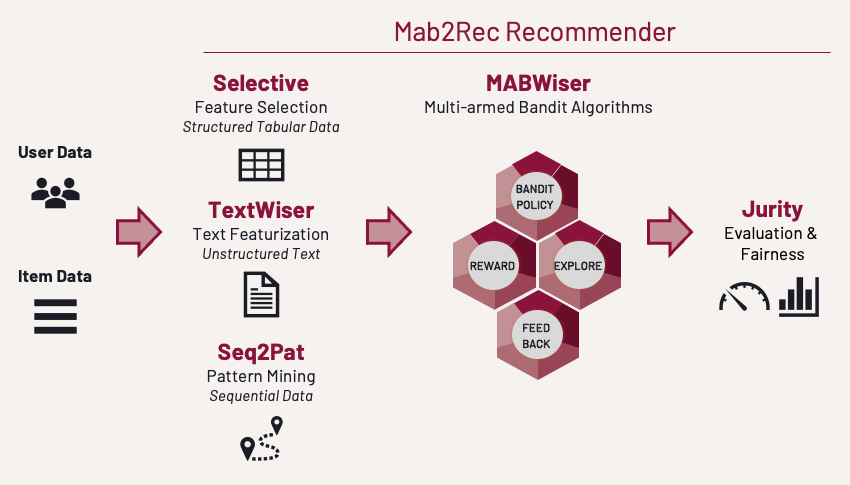
Mab2Rec is built on top of several other open-source software developed at the AI Center at Fidelity:
- MABWiser to create multi-armed bandit recommendation algorithms (IJAIT’21, ICTAI’19).
- TextWiser to create item representations via text featurization (AAAI’21).
- Selective to create user representations via feature selection.
- Seq2Pat to enhance users representations via sequential pattern mining (AAAI’22, KDF@AAAI’22, Frontiers’22)
- Jurity to evaluate recommendations including fairness metrics (ICMLA’21).
In this blog post, we start with a brief introduction to recommender systems, followed by the high-level design behind Mab2Rec. We then outline of each Mab2Rec component in the context of recommender systems. Finally, we provide a minimal example for training a recommender model from scratch using Mab2Rec.
The goal of this blog post is to provide data scientists and machine learning practitioners with a starting point in their efforts for building and deploying recommender models in industrial applications.
Introduction to Recommender Systems
The primary goal of recommender systems is to help users discover relevant content such as movies to watch, articles to read, or products to buy. Recommender systems learn users’ preferences from historical interactions to recommend the right content at the right time. In addition to historical interactions, some recommender systems also make use of contextual information about users and items.
Let us consider a movie recommender as a concrete example. In this scenario, we have a set of users, a set of items that correspond to movie titles, and a set of interactions that describe users’ implicit or explicit preference for movies. Each user is associated with contextual information. This information can be structured data of user attributes (e.g., subscription plan, device type, payment method, etc.) or semi-structured sequential data (e.g., list of the recent ratings given by a user). Analogously, each movie has content information. This can be unstructured data for each movie, such as text (e.g., synopses, movie reviews), image (e.g., cover art), audio (e.g., soundtrack), or video (e.g., trailer).
Most recommender systems are either content-based or collaborative systems. Content-based systems make recommendations using features of items a user has interacted with. They hypothesize that if a user was interested in an item in the past, they will be interested in similar items in the future. Collaborative filtering on that other hand uses similarities between users and items simultaneously to provide recommendations. Specifically, it assumes that if a user likes item A and another user likes the same item A as well as item B, the first user could also be interested in item B.
Beyond these traditional systems, there are a range of hybrid systems that make use of user-item interactions, user features, and item features in different ways to make recommendation. Examples of such systems include canonical deep learning-based recommender models such as Wide and Deep, Deep Cross Networks, DeepFM, and DLRM. These popular neural network models are based on two-tower architectures where two deep neural networks, referred to as towers, act as encoders to embed high-dimensional users’ and items’ features into a low-dimensional space that is used for prediction.

The Mab2Rec Approach
Mab2Rec advocates a modular approach that remains independent of any recommender system application. It is based on independent components for feature selection based on structured, semi-structured, sequential, and unstructured data, recommendation models, and performance and bias evaluation. This design allows each component to be self-contained and enables re-use across applications, even beyond recommender systems. Each component brings best-in-class techniques from the respective area that can plug and play with other parts in several ways. We can either utilize a single component or any complex combination of them. When the components are combined, it yields a powerful and scalable framework for building and deploying recommender applications as shown next.
Feature Selection & Generation
Contextual information is a key component of modern recommender systems. However, not all available contextual information is relevant or immediately usable within a recommender model. We need different approaches to extract useful features or representations depending on the type of data.
Structured Tabular Data
For industrial applications, it is common to have large amounts of raw tabular data. This is especially true for user contexts as most companies collect a wide range of attributes about users. It is a significant challenge to determine the most relevant features for a given recommender system application.
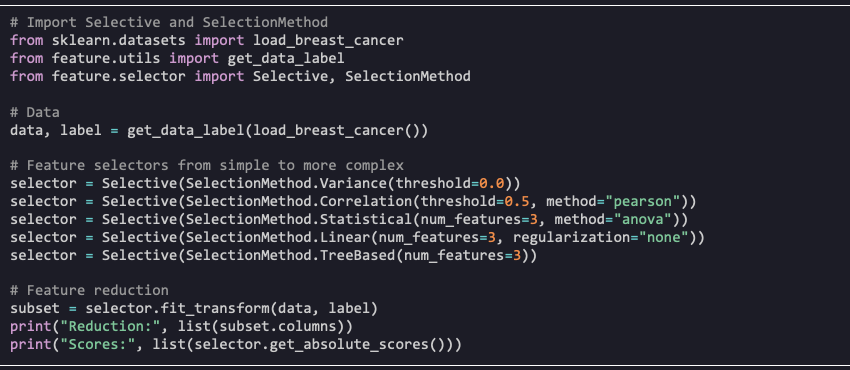
For this purpose, we open-sourced Selective a white-box feature selection library. In our recommenders setting, Selective helps determine the subset of tabular user features that are most relevant for predicting users’ item preference. The library offers a simple API and provides a variety of filtering and embedded selection methods with varying degrees of complexity, from simple variance, statistics- and correlation-based methods to embedded penalized linear regression models and non-linear tree-based methods.
In the example below, we perform feature selection on the Breast Cancer Dataset in the UCI Machine Learning Repository. The same approach can be adopted to identify user features that are most relevant for a given recommender system application.
Unstructured Text Data
Next, let us turn to unstructured text as a common data source for recommenders. Various text embeddings have become prevalent to consume raw text. However, there exists no silver bullet as to which featurization technique or combinations would provide the best performance for downstream applications. The choice of embedding techniques ranges widely, from simple counting-based TF-IDF to word embeddings like Word2Vec, Doc2Vec, and more sophisticated transformer language models like BERT and GPT-3. When faced with several options, benchmarking becomes imperative to find the best-performing technique. Beyond performance, other factors include inference time, simplicity, maintainability, hardware requirements, deployment constraints, and reproducibility.
To address this challenge, we open-sourced TextWiser (AAAI’21), a library that provides a unified framework for text featurization based on a rich set of methods. TextWiser introduced a novel context-free grammar that allows representing the language of all valid featurization techniques systematically and lends itself to a high-level user interface enabling rapid experimentation with various featurization methods. This serves as a building block within recommender applications consuming unstructured text.
In the example below, we demonstrate how different featurization methods can be used to convert textual data into numeric vectors that can be consumed by downstream machine learning models. In our movie-recommender example we can create item features from unstructured text such as movie synopses and reviews.

Semi-Structured Sequential Data
The other data type we consider is semi-structured sequential data, particularly sequential clickstream, to better understand the digital behavior of users. In recommenders, the typical usage of sequential data is to capture the behavior of a user over time and to include these as contextual user features in the model. Recent efforts to deal with sequential data include CNN-based Caser, RNN-based GRU4Rec and Transformer4Rec. All these approaches utilize deep neural networks and advanced architectures to exploit semi-structured input.
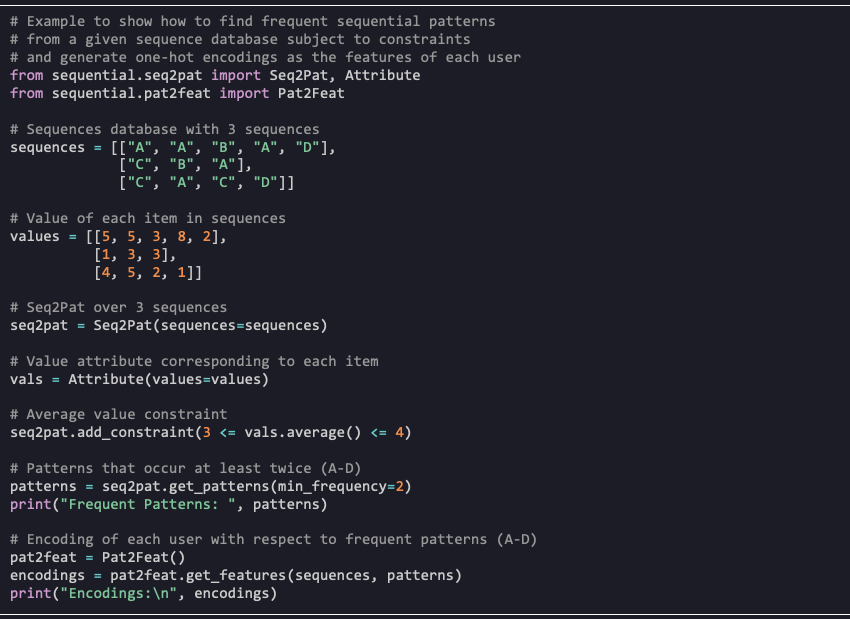
We propose an alternative approach based on sequential pattern mining as embodied in our open-source Seq2Pat library (AAAI’22, KDF@AAAI’22, Frontiers’22) to support industrial applications. Seq2Pat allows discovering sequential patterns that occur frequently in large sequence databases. It also supports constraint-based reasoning to specify desired properties over patterns. The embeddings of sequences are based on mined frequent patterns and can be used as features in downstream modeling tasks.
In the example below, we show how to find frequent sequential patterns from a given sequence database subject to constraints. We then generate one-hot encodings from the identified patterns, making it ready for consumption in downstream machine learning tasks. In our movie-recommender example, the sequences could be previous movies a user viewed.
Recommendation Models
So far we covered the input space. Given the input features, the ultimate goal is to create a content- and context-aware recommenders. In RecSys, focusing purely on exploitation fails capturing the dynamic nature of the user preferences and available items and lacks a principled method to explore different policies for continuous learning.
To balance the exploration-exploitation trade-off, we turn to Multi-Armed Bandits (MAB), a well-known family of policies that focuses on sequential decision-making. MAB algorithms define each arm as a decision that an agent can make, generating a deterministic or stochastic reward. In recommender systems, the arms correspond to the different items in the system, and the reward is based on user interactions with the suggested items, e.g., click or no-click. Contextual Multi-Armed Bandits (CMAB) utilize a state or context that captures side information that might affect the reward for a given arm.
To take advantage of CMAB algorithms, we open-sourced MABWiser (IJAIT’21, ICTAI’19) a Python-native library that offers context-free, non-parametric, and parametric MAB algorithms. Context-free and parametric contextual bandits are available through a learning policy. Non-parametric contextual bandits are available through a neighborhood policy used in combination with a learning policy. This design allows combining parametric policies with non-parametric ones leading to novel hybrid strategies.
In the example below, we show how to train a bandit using a context-free learning policy and then generate predictions.

Performance Evaluation
Recommender systems have been evaluated in many, often incomparable, ways. While the literature on recommender system evaluation offers a large variety of evaluation metrics, little guidance is provided on how to choose among them. We also often find inconsistent implementations for the same metric in open-source software. Since there is no single metric to evaluate the quality of a recommender system algorithm, it is typically required to consider several performance evaluation methods.
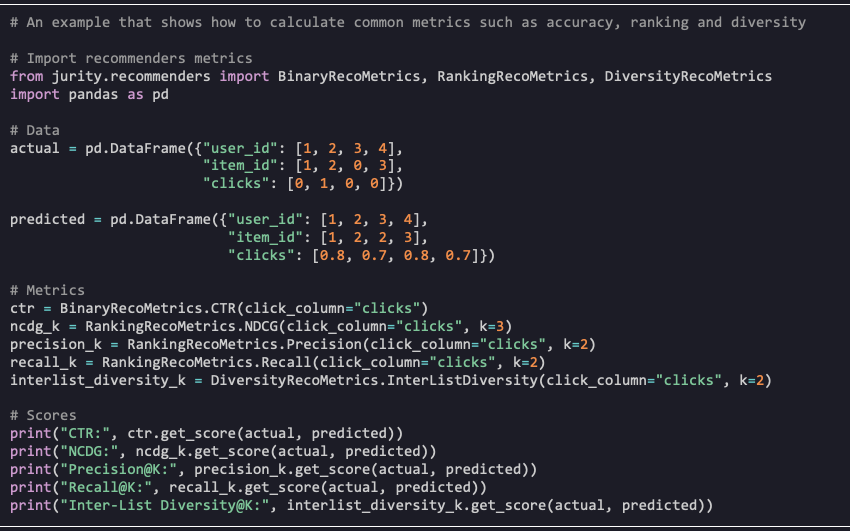
To this end, we open-sourced Jurity, a Python library that supports recommendation evaluation, fairness metrics and bias mitigation techniques. For offline performance evaluation, Jurity includes a range of accuracy, ranking, and diversity related metrics. For fairness evaluation, we extend binary metrics such as Disparate Impact and Statistical Parity to the multi-class, multi-label setting of recommender systems.
Mab2Rec
Mab2Rec ties all of the individual components together and orchestrates feature selection and generation, recommendation models, and performance evaluation to allow rapid prototyping. This modular end-to-end framework embraces the creativity of data scientists and provides them the tools and the suitable paradigm with several options to utilize rich types of data, train and select from many available models, and evaluate the quality of the final solution.
Mab2Rec supports all bandit algorithms available in MABWiser and allows users to prototype single bandit algorithm or to benchmark multiple bandit algorithms. In concert with the feature selection and engineering capabilities from Selective, TextWiser, and Seq2Pat as well as fairness and performance evaluation from Jurity, it offers a sophisticated and flexible toolchain for building recommender models.
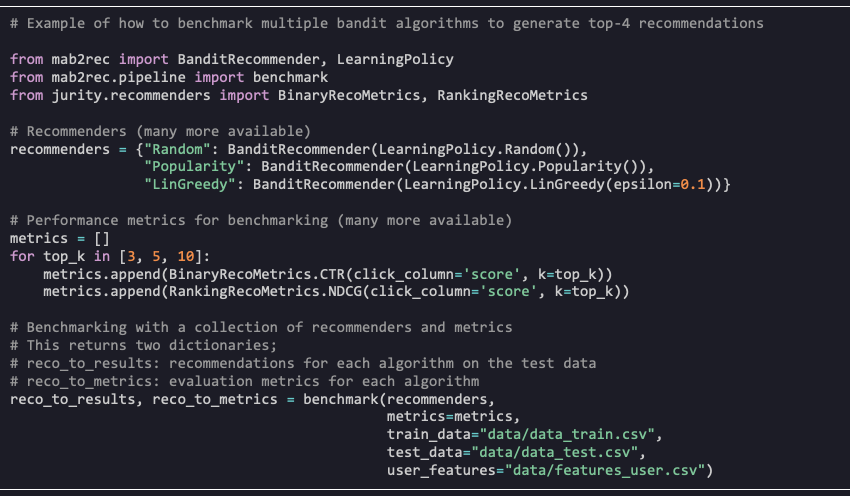
In the example below we show how to benchmark multiple bandit algorithms on the famous MovieLens 100K dataset (download). By considering different recommender policies and parameter configurations one can quickly prototype different algorithms and use the evaluation metrics to find the best performing candidates.
What’s next?
To get started, install Mab2Rec via pip install mab2rec and run the Quick Start examples!
Next, see our extensive Tutorial Notebooks with guidelines on building recommenders, performing model selection, and evaluating performance, using the MovieLens dataset as an example application.
Remember to star our Mab2Rec GitHub Repo to help share with others and stay informed of latest developments.
The Featured Blog Posts series will highlight posts from partners and members of the All Things Open community leading up to the conference in the fall.